日文编码系统与乱码关系解析,日文编码系统与乱码关系是怎样的?
在当今数字化时代,信息交流变得日益频繁。在处理日文文本时,我们常常会遇到乱码的问题。这不仅令人困扰,还可能导致信息的误解或丢失。那么,日文编码系统与乱码之间究竟存在怎样的关系呢?将深入探讨这一问题。
日文编码系统的发展历程
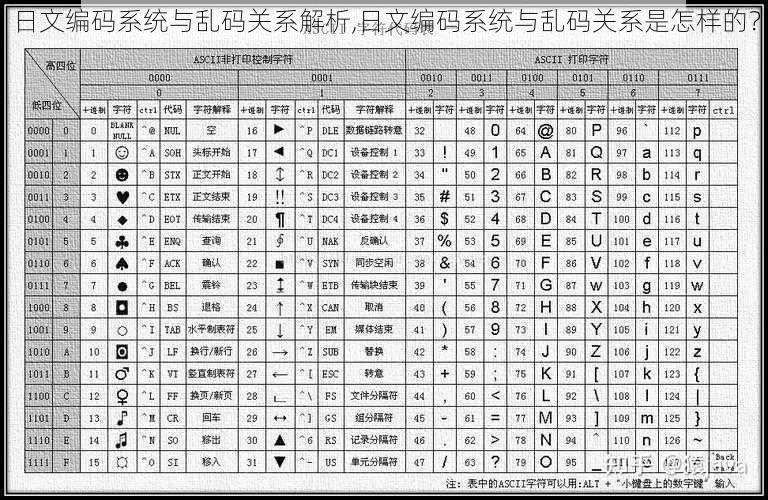
要理解日文编码系统与乱码的关系,首先需要了解日文编码系统的发展历程。在过去,由于计算机技术的限制,日文的编码方式较为复杂。随着时间的推移,各种编码标准不断涌现,如 Shift_JIS、EUC-JP 等。这些编码标准在不同的时期和应用场景中得到了广泛使用。
乱码的产生原因
乱码的产生主要有以下几个原因:
1. 编码不匹配:当使用的编码方式与文本实际使用的编码方式不一致时,就会出现乱码。
2. 字符集不完整:某些字符可能不在当前使用的字符集中,导致无法正确显示。
3. 数据损坏:在传输或存储过程中,数据可能遭到损坏,从而导致乱码。
常见的日文编码系统
1. Shift_JIS:Shift_JIS 是日本广泛使用的一种编码系统,主要用于显示日文文本。
2. EUC-JP:EUC-JP 是另一种常用的日文编码系统,与 Shift_JIS 类似,但在一些细节上有所不同。
3. UTF-8:UTF-8 是一种通用的字符编码标准,也可以用于表示日文。
解决乱码的方法
为了解决乱码问题,可以采取以下几种方法:
1. 选择正确的编码方式:在处理日文文本时,确保使用与文本实际使用的编码方式一致的编码。
2. 进行字符集转换:如果遇到字符集不完整的情况,可以使用字符集转换工具将文本转换为支持的字符集。
3. 检查数据完整性:在传输和存储日文文本时,要确保数据的完整性,避免数据损坏。
未来的发展趋势
随着技术的不断进步,日文编码系统也在不断发展和完善。未来,可能会出现更加高效和通用的编码标准,以更好地支持日文文本的处理和交流。
日文编码系统与乱码之间存在着密切的关系。了解日文编码系统的发展历程、乱码的产生原因以及解决乱码的方法,对于正确处理日文文本至关重要。在数字化时代,我们应该重视日文编码问题,以确保信息的准确传递和交流。
以上是根据你的要求生成,希望对你有所帮助。如果你还有其他问题,请随时提问。
相关文章
-

ysl蜜桃色7788 YSL 蜜桃色 7788,谁涂谁好看的人间水蜜桃
-

胸一面膜上边一面膜下边日本_胸一面膜上边一面膜下边日本:日本胸部面膜的奥秘
-

蜜芽188cnn网站入口(蜜芽 188cnn 网站入口:成人内容,未满 18 岁禁止访问)
-
手指扣喷的技巧视频教程,手指扣喷的技巧视频教程:简单易学的扣喷方法
-

土豪漫画免费观看在线阅读—土豪漫画免费观看在线阅读,无广告弹窗,精彩不断
-

男生和女生在一起错错错30分钟电视剧预告片、男生和女生在一起错错错 30 分钟电视剧预告片
-

写的特别细的开车PO推荐文多人-写的特别细的开车 PO 推荐文多人,教你如何安全驾驶
-

成品禁用短视频app下载【成品短视频 app 为何被禁用?下载需谨慎】